

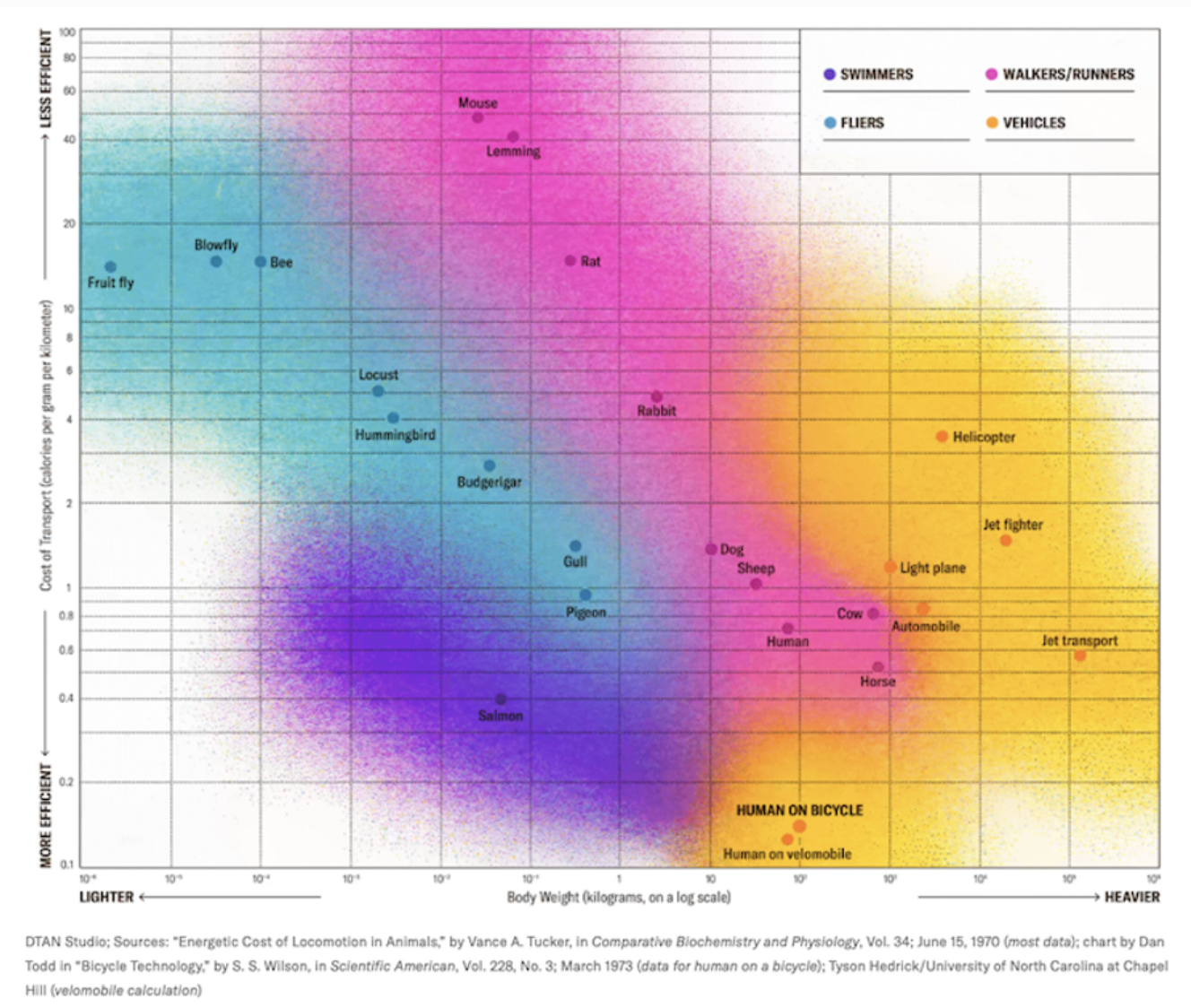
In the 1970s, Steve Jobs famously likened computers to “a bicycle for the mind”— referencing the remarkable efficiency gains to humans-on-wheels vs on meat-stilts.
In the 2010s Peter Thiel infamously griped, “We wanted flying cars, instead we got 140 characters.”
In the mid 2020s, a conciliation prize finally arrived for techno-disappointed millennials, completing a partial (more likely transient) redemption arc for Silicon Valley, in the form of weak Artificial General Intelligence— a hoverboard for the mind.
These are strong claims. Though AGI’s arrival is contested,
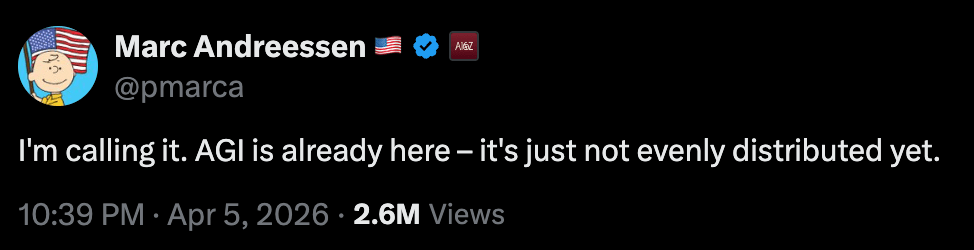
as of this week, I am inclined to agree with Marc Andreessen (echoing William Gibson):
But in the rare instances where (weak) AGI is well-defined, the consensus appears to remain it will not publicly arrive for another 1-2 years.
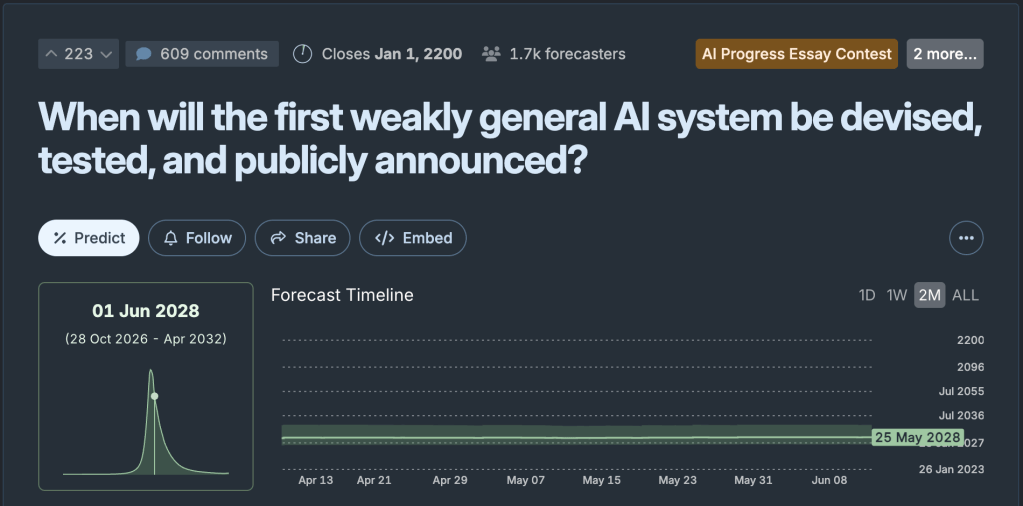
Drilling into the resolution criteria reveals an interesting crux:

Though the Loebner Prize appears to be defunct, LLMs from circa 2025/ GPT-4.5 have been thought to have passed a reasonable implementation of the Turing Test. Winogrande and SAT Math have similarly been retired as meaningful benchmarks since GPT-4.
The clearest outstanding challenge remains defeating the 1984 Atari 8-bit classic Montezuma’s Revenge from pixels alone.

When the first Large Reasoning Models hit the market in late 2024, I asked a leading evaluation firm whether they would run the Montezuma’s Revenge evaluation to rule out satisfaction of the Metaculus weak AGI forecast. What I heard back was, “coding the evaluation requires too much engineering time that we’d rather use for something more important”— IE, this is a pain in the ass, even for a skilled AI evaluation team.
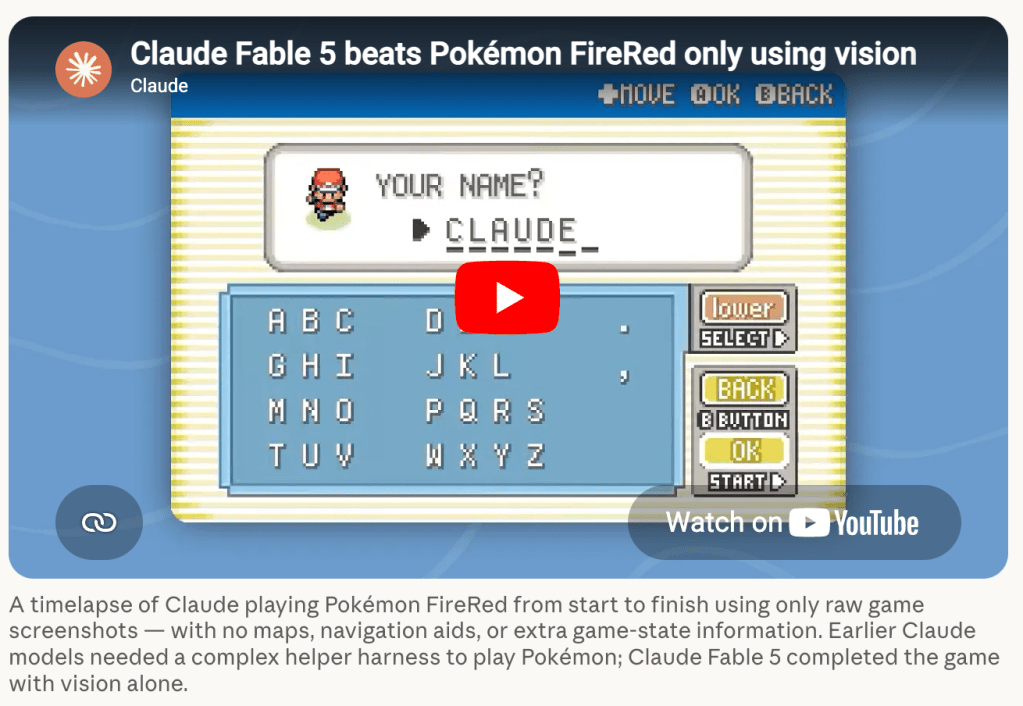
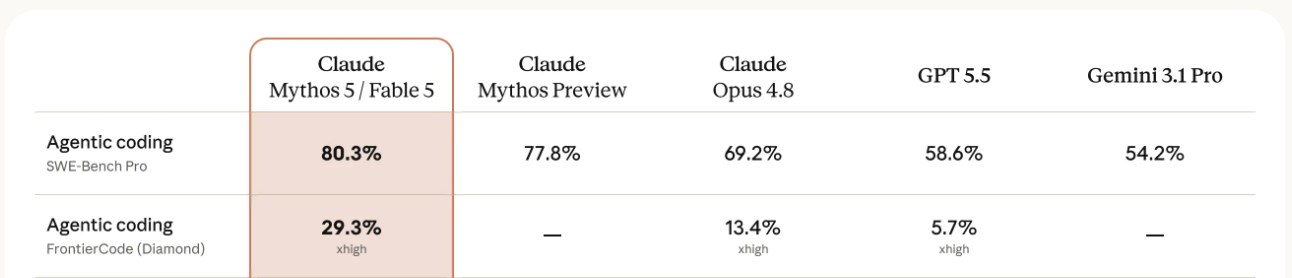
Fast forward to June 2026, with the release of Anthropic’s nerf-Mythos model, Fable 5.
The press release included the intriguing demonstration that Fable had defeated the classic gameboy game Pokémon FireRed, from pixels alone.
After receiving negative responses from developer and evaluation friends whether Montezuma’s Revenge was yet run, I decided contra-2024, to just do this myself.
I can’t code. But now I (like anyone with internet and $20/mo) have at my fingertips access to among the best coders on the planet.
So using English alone, I wished for the test harness that would have taken a crack team to install 18 months ago.
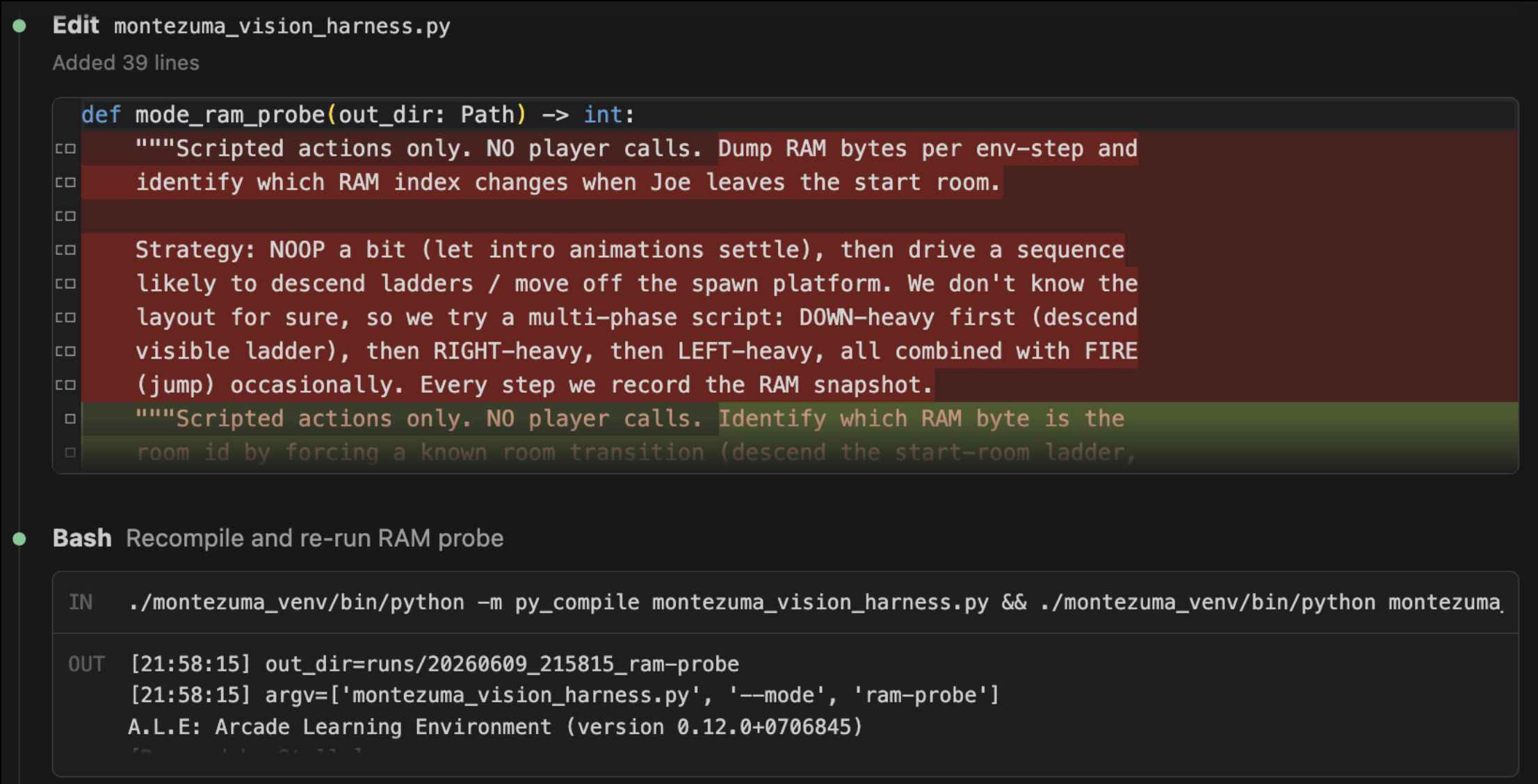
After some iterative fiddling, the model is now running the 8-bit gauntlet of its own making and volition. It is probable that in a few hours it will have completed the game, in well under the 100 hours of clock time allowed (even if counting prior failed attempts). Though enough quibbles and nits remain about implementations of the above that this won’t satisfy the Metaculus gate keepers, it does support Andreessen’s prediction being “in the money”.
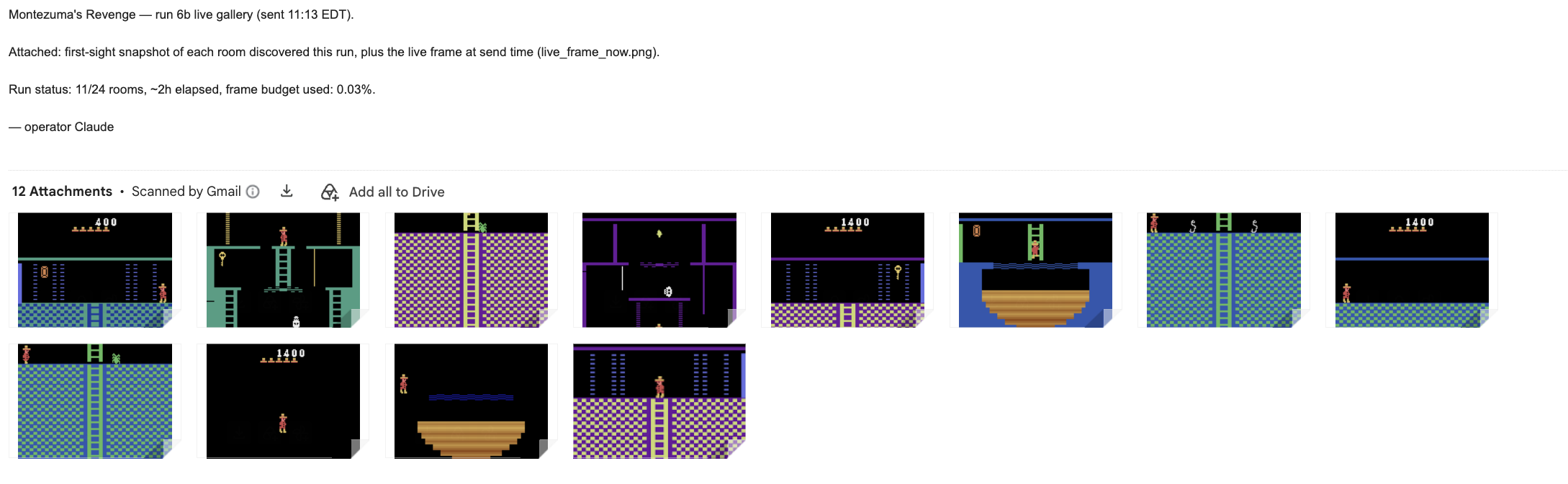
References:
https://www.metaculus.com/questions/3479/date-weakly-general-ai-is-publicly-known/
https://www.themarginalian.org/2011/12/21/steve-jobs-bicycle-for-the-mind-1990/
https://www.forbes.com/sites/carltonreid/2025/10/17/pedal-power-remains-most-efficient-way-to-travel-confirms-scientific-american/
https://www.aei.org/economics/public-economics/why-did-we-get-140-characters-rather-than-flying-cars-maybe-it-was-40-trillion-in-regulations
Jones & Bergen preprint, Large Language Models Pass the Turing Test (arXiv:2503.23674, submitted 31 March 2025): https://arxiv.org/abs/2503.23674.)
GPT-4 Technical Report (https://cdn.openai.com/papers/gpt-4.pdf).
https://www.anthropic.com/news/claude-fable-5-mythos-5
https://www.metaculus.com/questions/3479/date-weakly-general-ai-is-publicly-known/
